ID:NAB1_HUMAN DESCRIPTION: RecName: Full=NGFI-A-binding protein 1; AltName: Full=EGR-1-binding protein 1; AltName: Full=Transcriptional regulatory protein p54; FUNCTION: Acts as a transcriptional repressor for zinc finger transcription factors EGR1 and EGR2 (By similarity). SUBUNIT: Homomultimers may associate with EGR1 bound to DNA (By similarity). SUBCELLULAR LOCATION: Nucleus (By similarity). TISSUE SPECIFICITY: Isoform Short is found in a myeloid leukemia cell line. DOMAIN: The NAB conserved domain 1 (NCD1) interacts with EGR1 inhibitory domain and mediates multimerization. DOMAIN: The NAB conserved domain 2 (NCD2) is necessary for transcriptional repression. SIMILARITY: Belongs to the NAB family.
Aorta Christopher J O'Donnell et al. BMC medical genetics 2007, Genome-wide association study for subclinical atherosclerosis in major arterial territories in the NHLBI's Framingham Heart Study., BMC medical genetics.
[PubMed 17903303]
The results from this GWAS generate hypotheses regarding several SNPs that may be associated with SCA phenotypes in multiple arterial beds. Given the number of tests conducted, subsequent independent replication in a staged approach is essential to identify genetic variants that may be implicated in atherosclerosis.
Blood Pressure Daniel Levy et al. BMC medical genetics 2007, Framingham Heart Study 100K Project: genome-wide associations for blood pressure and arterial stiffness., BMC medical genetics.
[PubMed 17903302]
These results of genome-wide association testing for blood pressure and arterial stiffness phenotypes in an unselected community-based sample of adults may aid in the identification of the genetic basis of hypertension and arterial disease, help identify high risk individuals, and guide novel therapies for hypertension. Additional studies are needed to replicate any associations identified in these analyses.
Liver Cirrhosis, Biliary George F Mells et al. Nature genetics 2011, Genome-wide association study identifies 12 new susceptibility loci for primary biliary cirrhosis., Nature genetics.
[PubMed 21399635]
The RNAfold program from the Vienna RNA Package is used to perform the secondary structure predictions and folding calculations. The estimated folding energy is in kcal/mol. The more negative the energy, the more secondary structure the RNA is likely to have.
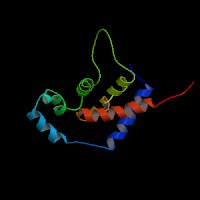
ModBase Predicted Comparative 3D Structure on Q13506
Front
Top
Side
The pictures above may be empty if there is no ModBase structure for the protein. The ModBase structure frequently covers just a fragment of the protein. You may be asked to log onto ModBase the first time you click on the pictures. It is simplest after logging in to just click on the picture again to get to the specific info on that model.
Orthologous Genes in Other Species
Orthologies between human, mouse, and rat are computed by taking the best BLASTP hit, and filtering out non-syntenic hits. For more distant species reciprocal-best BLASTP hits are used. Note that the absence of an ortholog in the table below may reflect incomplete annotations in the other species rather than a true absence of the orthologous gene.
 US Server
US Server