Description: Homo sapiens nuclear VCP-like (NVL), transcript variant 1, mRNA. RefSeq Summary (NM_002533): This gene encodes a member of the AAA (ATPases associated with diverse cellular activities) superfamily. Multiple transcript variants encoding different isoforms have been found for this gene. Two encoded proteins, described as major and minor isoforms, have been localized to distinct regions of the nucleus. The largest encoded protein (major isoform) has been localized to the nucleolus and shown to participate in ribosome biosynthesis (PMID: 15469983, 16782053), while the minor isoform has been localized to the nucleoplasmin. [provided by RefSeq, Aug 2011]. Transcript (Including UTRs) Position: hg19 chr1:224,415,036-224,517,891 Size: 102,856 Total Exon Count: 23 Strand: - Coding Region Position: hg19 chr1:224,415,328-224,517,829 Size: 102,502 Coding Exon Count: 23
Depressive Disorder, Major N R Wray et al. Molecular psychiatry 2012, Genome-wide association study of major depressive disorder: new results, meta-analysis, and lessons learned., Molecular psychiatry.
[PubMed 21042317]
The RNAfold program from the Vienna RNA Package is used to perform the secondary structure predictions and folding calculations. The estimated folding energy is in kcal/mol. The more negative the energy, the more secondary structure the RNA is likely to have.
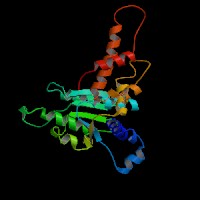
ModBase Predicted Comparative 3D Structure on O15381
Front
Top
Side
The pictures above may be empty if there is no ModBase structure for the protein. The ModBase structure frequently covers just a fragment of the protein. You may be asked to log onto ModBase the first time you click on the pictures. It is simplest after logging in to just click on the picture again to get to the specific info on that model.
Orthologous Genes in Other Species
Orthologies between human, mouse, and rat are computed by taking the best BLASTP hit, and filtering out non-syntenic hits. For more distant species reciprocal-best BLASTP hits are used. Note that the absence of an ortholog in the table below may reflect incomplete annotations in the other species rather than a true absence of the orthologous gene.
 US Server
US Server